import cv2
from PIL import Image # 画像処理ライブラリ
from matplotlib import pyplot as plt # データプロット用ライブラリ
import numpy as np # データ分析用ライブラリ
import os # os の情報を扱うライブラリ
import pytesseract # tesseract の python 用ライブラリ
import unicodedata
from pytesseract import Output
def remove_control_characters(s):
return "".join(ch for ch in s if unicodedata.category(ch)[0]!="C")
# 以下の値は汎用性ナシ。
dx,dy=52,52
ox,oy=10,10
tD,tB=38,38
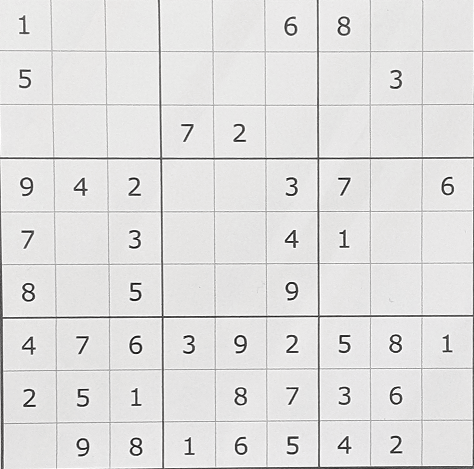
pz='100006800500000030000720000942003706703004100805009000476392581251087360098165420'
img = cv2.imread("/home/mars/TEST50-2a.png")
#cv2.imshow('sudoku',img)
ok,ng=0,0
for x in range(9):
for y in range(9):
t=x*dx + ox
b=y*dy+oy
tt=t-2
bb=b-2
#cv2.rectangle(img,(t,b),(t+tD,b+tB),(0,0,255))
sliced=img[tt:t+tD,bb:b+tB]
#sliced=cv2.threshold(tmp, 150, 255, cv2.THRESH_BINARY)
im_list = np.array(sliced)
img_rgb = cv2.cvtColor(im_list, cv2.COLOR_BGR2RGB)
pos=str(x)+','+str(y)
#txt = pytesseract.image_to_string(im_list,lang="jpn",config='--psm 10 outputbase digits')
txt=pytesseract.image_to_string(sliced, config='-l eng --psm 6 outputbase digits')
junk=remove_control_characters(txt)
#print(x,y,len(junk))
ans=pz[x*9+y]
if len(junk)<1:
if ans=='0':
ok=ok+1
junk='O'
else:
junk='X'
ng=ng+1
else:
if ans==junk:
ok=ok+1
else:
junk='X'
ng=ng+1
out=out+junk+'('+ans+')'
#cv2.imshow('slice:'+pos,sliced)
print(str(x)+'--->',out,' correct=',ok,' in-correct=',ng)
out=''
#cv2.imshow('slice',img)
print('Success rate:',round(100*ok/81,2),'[%]')
print('done')正答率:86%
0---> 1(1)O(0)O(0)O(0)O(0)6(6)8(8)O(0)O(0) correct= 9 in-correct= 0
1---> X(5)O(0)O(0)O(0)X(0)O(0)O(0)3(3)O(0) correct= 16 in-correct= 2
2---> O(0)O(0)O(0)X(7)2(2)O(0)O(0)O(0)O(0) correct= 24 in-correct= 3
3---> 9(9)4(4)2(2)O(0)O(0)3(3)X(7)O(0)6(6) correct= 32 in-correct= 4
4---> 7(7)O(0)3(3)O(0)O(0)4(4)X(1)O(0)O(0) correct= 40 in-correct= 5
5---> 8(8)X(0)5(5)O(0)X(0)9(9)O(0)O(0)O(0) correct= 47 in-correct= 7
6---> 4(4)7(7)6(6)3(3)9(9)2(2)5(5)8(8)X(1) correct= 55 in-correct= 8
7---> X(2)5(5)X(1)O(0)8(8)7(7)3(3)6(6)O(0) correct= 62 in-correct= 10
8---> O(0)9(9)8(8)X(1)6(6)5(5)4(4)2(2)O(0) correct= 70 in-correct= 11
Success rate: 86.42 [%]
done