$sudo apt-get update
$sudo apt install chromium-chromedriver
$sddo cp /usr/lib/chromium-browser/chromedriver /usr/bin
$pip install selenium
$pip install webdriver_manager紛らわしい点:webdriver_managerとwebdrivermanagerの両方が存在し、機能が同じではない。webdriver_managerの方が良さそう。
Webサイトのタイトルを取得してみる。
from selenium import webdriver
import time
#---------------------------------------------------------------------------------------
# 処理開始
#---------------------------------------------------------------------------------------
# ブラウザをheadlessモード実行
print("\nブラウザを設定")
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver',options=options)
driver.implicitly_wait(10)
# サイトにアクセス
print("サイトにアクセス開始")
URL="https://rfsec.ddns.net/db/"
driver.get(URL)
time.sleep(3)
# driver.find_elements_by_css_selector("xxx") 的な処理を自由に
print("サイトのタイトル:", driver.title)認証があるサイトの場合(中華製ネットワークカメラ)
import time
import base64
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
def get_auth_header(user, password):
b64 = "Basic " + base64.b64encode('{}:{}'.format(user, password).encode('utf-8')).decode('utf-8')
return {"Authorization": b64}
# Webdriver ManagerでChromeDriverを取得
driver = webdriver.Chrome(executable_path=ChromeDriverManager().install())
# Authorizationヘッダを付与
driver.execute_cdp_cmd("Network.enable", {})
driver.execute_cdp_cmd("Network.setExtraHTTPHeaders", {"headers": get_auth_header("admin", "")})
# Basic認証が必要なページにアクセス
driver.get('http://192.168.68.128')
time.sleep(5)
driver.close()
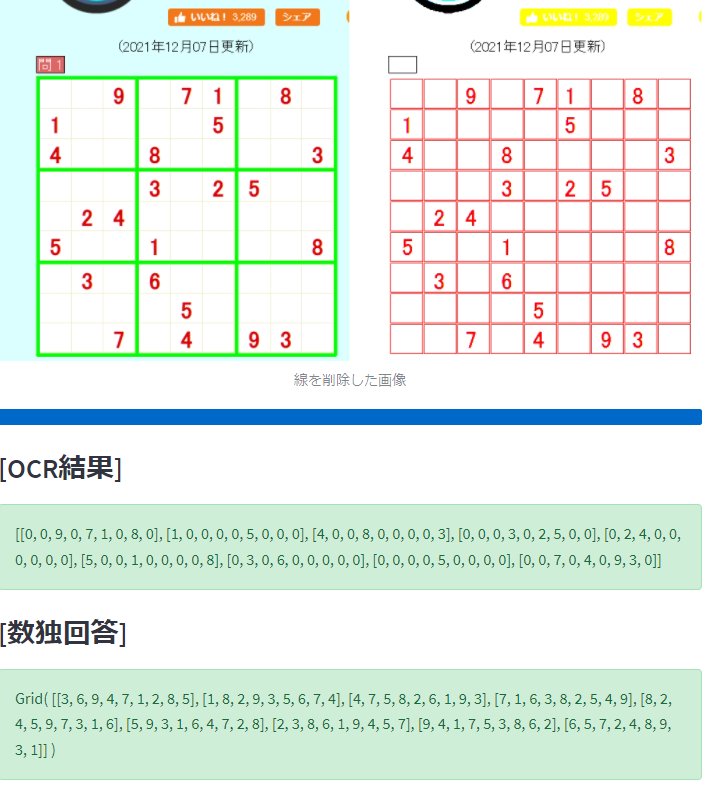
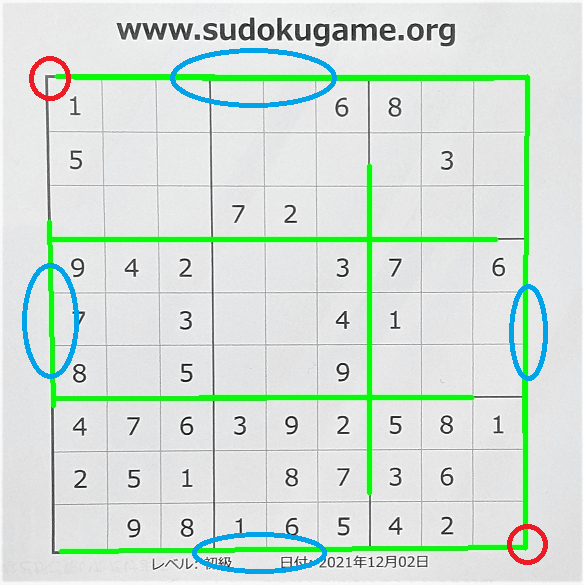
driver.quit()数独の問題サイトから問題を取得して、解く。
# ここからがseleniumのコード
# 問題サイト http://numberplace.net/
#
from selenium import webdriver
import time
import numpy as np
def disp(results):
msg=""
for r in results:
for y in range(9):
for x in range(9):
c = r._values[y][x]
c = str(c)
d = row2[y][x]
if d != 0:
msg=msg+'('+ c + ') '
else:
msg=msg+'-'+ c + '- '
msg=msg+"\n"
print(msg)
#---------------------------------------------------------------------------------------
# 処理開始
#---------------------------------------------------------------------------------------
# ブラウザをheadlessモード実行
print("\nブラウザを設定")
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver',options=options)
driver.implicitly_wait(2)
# サイトにアクセス
for num in range(5):
URL="http://numberplace.net/?no="+str(num+1)
print("サイトにアクセス開始:",URL)
driver.get(URL)
time.sleep(2)
lines= driver.page_source.splitlines()
for line in lines:
if 'toi' in line:
q = line.split(' ')[3].replace("'","").replace(";","")
q=list(q)
#print(q)
qi = [int(s) for s in q]
#print(qi)
q2 = np.array(qi)
row2=np.array(q2).reshape(-1,9).tolist()
grid = solver.Grid(row2)
print(grid)
results = solver.solve_all(grid)
disp(results)
break
print('Done.')