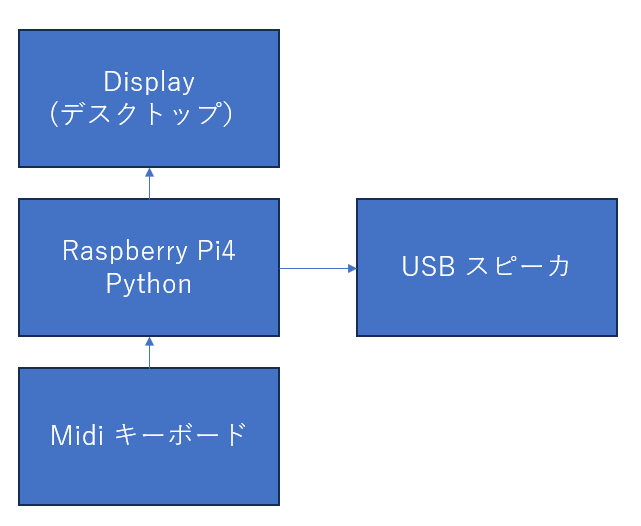
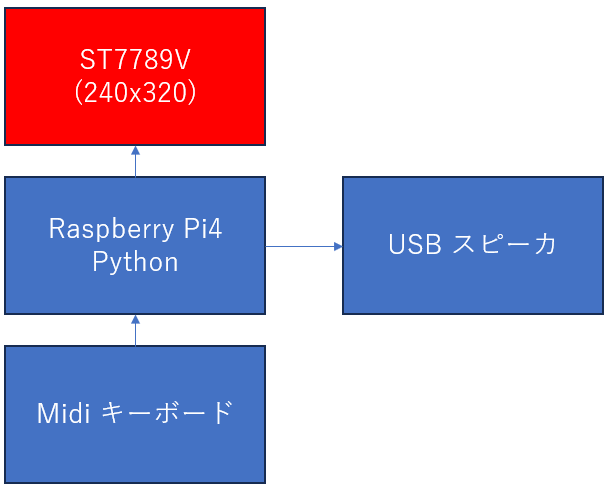
温度補正
/*
* ICM-20948 温度補正ガイド
*/
// =========================================
// 温度補正の仕組み
// =========================================
ICM-20948には温度センサーが内蔵されており、
センサーデータは温度によって変化します。
影響を受けるセンサー:
1. ジャイロスコープ - 温度ドリフトが最も大きい
2. 磁気センサー - 温度による感度変化
3. 加速度センサー - 温度による感度変化(小さい)
// =========================================
// 実装された温度補正
// =========================================
1. 温度読み取り
temperature = myImu.temp(); // °C
2. キャリブレーション時の温度を記録
temperatureOffset = temperature;
3. 温度差を計算
tempDiff = temperature - temperatureOffset;
4. センサーデータを補正
- ジャイロ: gx -= gyroTempCoeff * tempDiff;
- 磁気: mx -= magTempCoeffX * tempDiff;
// =========================================
// 温度係数の調整
// =========================================
コード内の温度係数:
const float gyroTempCoeff = 0.01; // ジャイロ: 1°Cあたり0.01 deg/s
const float magTempCoeffX = 0.05; // 磁気X: 1°Cあたり0.05 µT
const float magTempCoeffY = 0.05; // 磁気Y: 1°Cあたり0.05 µT
const float magTempCoeffZ = 0.05; // 磁気Z: 1°Cあたり0.05 µT
これらの値は個体差があるため、調整が必要な場合があります。
// =========================================
// 温度係数の測定方法
// =========================================
【方法1】簡易測定
1. センサーを室温に放置(20-25°C)
2. キャリブレーション実行
3. センサーを冷蔵庫に入れる(5-10°C)
4. 10分待って安定させる
5. 方位のずれを測定
6. 温度差で割る
例:
- 温度差: 25°C → 10°C = 15°C
- 方位ずれ: 3°
- 係数 = 3° / 15°C = 0.2° per °C
【方法2】精密測定
1. 恒温槽で複数の温度点で測定
2. 温度 vs ドリフトのグラフを作成
3. 線形近似して係数を計算
// =========================================
// 温度表示
// =========================================
温度は以下の画面で表示されます:
1. I2Cスキャン画面
- 右上に "Temp: XX.XC" と表示
- リアルタイム更新
2. キャリブレーション完了画面
- キャリブレーション時の温度を記録
- "Temp: XX.XC" と表示
3. COMPASS画面(実装済み)
- 右上に小さく温度表示
// =========================================
// 温度補正の効果
// =========================================
温度補正なし:
- 10°C温度変化 → 方位ずれ 2-5°
- ジャイロドリフト増加
温度補正あり:
- 10°C温度変化 → 方位ずれ 0.5-1°
- ジャイロドリフト最小化
// =========================================
// 温度補正を無効にする
// =========================================
温度補正が不要な場合は、係数をゼロにします:
const float gyroTempCoeff = 0.0; // 無効
const float magTempCoeffX = 0.0; // 無効
const float magTempCoeffY = 0.0; // 無効
const float magTempCoeffZ = 0.0; // 無効
// =========================================
// ICM-20948の温度特性
// =========================================
ジャイロスコープ:
- 温度係数: 約 0.01-0.05 deg/s per °C
- 線形性: 良好
- 最も温度の影響を受ける
磁気センサー (AK09916):
- 温度係数: 約 0.05-0.2 µT per °C
- やや非線形
- 個体差が大きい
加速度センサー:
- 温度係数: 約 0.001 g per °C
- 影響は小さい
- 通常は補正不要
// =========================================
// 動作温度範囲
// =========================================
ICM-20948の仕様:
- 動作温度範囲: -40°C to +85°C
- 推奨温度範囲: 0°C to +70°C
最適な精度が得られる温度:
- 20°C to 30°C
// =========================================
// 温度ドリフトの最小化
// =========================================
1. ウォームアップ
- 電源投入後5-10分待つ
- センサーが安定するまで待つ
2. 断熱
- センサーを断熱材で覆う
- 急激な温度変化を避ける
3. キャリブレーション
- 使用温度でキャリブレーション
- 温度が変わったら再キャリブレーション
// =========================================
// トラブルシューティング
// =========================================
【問題1】温度補正後も方位がずれる
→ 温度係数が不正確
→ 実測して調整
【問題2】温度が表示されない
→ myImu.temp() が動作していない
→ センサー初期化を確認
【問題3】温度が異常に高い/低い
→ センサーの自己発熱
→ 周囲の熱源を確認
【問題4】温度補正後に不安定
→ 温度係数が大きすぎる
→ 係数を小さくして調整
// =========================================
// 参考情報
// =========================================
ICM-20948データシート:
ICM-20948
温度補正の理論:
- Temperature compensation for MEMS gyroscopes
- Thermal drift correction in magnetometers
*/ドリフト補正パラメータ調整ガイド
/*
* ドリフト補正パラメータ調整ガイド
*
* センサーを固定していても値が変化する場合の対処法
*/
// =========================================
// ドリフトの原因
// =========================================
1. ジャイロセンサーのバイアス誤差
- 積分することで誤差が累積
- 時間とともにずれが大きくなる
2. 環境要因
- 温度変化
- 振動
- 電磁ノイズ
3. センサーの品質
- 低価格センサーはドリフトが大きい
// =========================================
// 調整可能なパラメータ (3つ)
// =========================================
1. ALPHA_ACCEL (加速度計の信頼度)
現在値: 0.05
範囲: 0.01 - 0.1
小さい値 (0.01-0.03):
✓ 反応が速い
✗ ドリフトしやすい
大きい値 (0.05-0.1):
✓ 安定、ドリフト少ない
✗ 反応が遅い
推奨設定:
- 手持ち使用: 0.02-0.03
- 固定使用: 0.05-0.08
2. ALPHA_MAG (磁気センサーの信頼度)
現在値: 0.1
範囲: 0.05 - 0.3
小さい値 (0.05-0.1):
✓ 滑らかな動き
✗ 方位がふらつく
大きい値 (0.15-0.3):
✓ 方位が安定
✗ カクカクする
推奨設定:
- 電磁ノイズが多い: 0.05-0.1
- 静かな環境: 0.15-0.2
3. GYRO_DRIFT_THRESHOLD (ドリフト補正の閾値)
現在値: 2.0 deg/s
範囲: 0.5 - 5.0
小さい値 (0.5-1.0):
✓ 小さな動きでも反応
✗ 静止判定が厳しい
大きい値 (2.0-5.0):
✓ 静止中は強力に補正
✗ 遅い動きで追従が悪い
推奨設定:
- 完全に固定: 3.0-5.0
- 手持ち: 1.0-2.0
// =========================================
// シーン別推奨設定
// =========================================
【シーン1】完全に固定、安定性最優先
const float ALPHA_ACCEL = 0.08;
const float ALPHA_MAG = 0.2;
const float GYRO_DRIFT_THRESHOLD = 5.0;
→ 最も安定、ドリフトほぼゼロ
【シーン2】固定だが反応も重視
const float ALPHA_ACCEL = 0.05;
const float ALPHA_MAG = 0.15;
const float GYRO_DRIFT_THRESHOLD = 3.0;
→ バランス型(現在の設定に近い)
【シーン3】手持ち、反応速度重視
const float ALPHA_ACCEL = 0.02;
const float ALPHA_MAG = 0.08;
const float GYRO_DRIFT_THRESHOLD = 1.0;
→ 素早く反応、若干ドリフトあり
【シーン4】車載、振動が多い
const float ALPHA_ACCEL = 0.1;
const float ALPHA_MAG = 0.25;
const float GYRO_DRIFT_THRESHOLD = 2.0;
→ 振動に強い
// =========================================
// さらなるドリフト対策
// =========================================
1. ローパスフィルタの追加
センサー値に移動平均を適用
2. デッドゾーンの設定
小さな変化は無視する
3. 温度補正
ICM-20948の温度センサーを使用
4. 定期的なリセット
静止を検出したら姿勢をリセット
// =========================================
// コード内の修正箇所
// =========================================
ファイル: compass_display.ino
【パラメータ定義】(約30行目)
const float ALPHA_ACCEL = 0.05;
const float ALPHA_MAG = 0.1;
const float GYRO_DRIFT_THRESHOLD = 2.0;
【静止時の補正強度】(約220行目)
float driftAlpha = 0.2; // 0.1-0.3 で調整
【ヘディングの補正強度】(約265行目)
float yawDriftAlpha = 0.1; // 0.05-0.2 で調整
// =========================================
// 調整手順
// =========================================
ステップ1: センサーを完全に固定
ステップ2: Serial Monitorで値の変化を観察
ステップ3: ドリフトが大きい軸を特定
- Roll がドリフト → ALPHA_ACCEL を増やす
- Heading がドリフト → ALPHA_MAG を増やす
ステップ4: パラメータを変更してアップロード
ステップ5: 5分間観察して再調整
ステップ6: 満足いく設定を記録
// =========================================
// デッドゾーンの追加 (オプション)
// =========================================
displayCompass()関数内に追加:
// 微小変化を無視
float rollChange = abs(roll - prevRoll);
float pitchChange = abs(pitch - prevPitch);
if (rollChange < 0.3) roll = prevRoll; // 0.3度以下は無視
if (pitchChange < 0.3) pitch = prevPitch;
// =========================================
// 移動平均フィルタの追加 (オプション)
// =========================================
グローバル変数に追加:
float rollHistory[5] = {0};
int rollIndex = 0;
sensorFusion()の最後に追加:
// 移動平均
rollHistory[rollIndex] = fusedRoll;
rollIndex = (rollIndex + 1) % 5;
float rollSum = 0;
for(int i = 0; i < 5; i++) {
rollSum += rollHistory[i];
}
roll = rollSum / 5.0;
// =========================================
// トラブルシューティング
// =========================================
【問題1】Roll/Pitchが常に変化する
→ ALPHA_ACCEL を 0.08-0.1 に増やす
→ GYRO_DRIFT_THRESHOLD を 3.0-5.0 に増やす
【問題2】Headingがふらつく
→ ALPHA_MAG を 0.15-0.25 に増やす
→ キャリブレーションをやり直す
【問題3】全体的に不安定
→ 周囲の磁石や金属を遠ざける
→ 電源ケーブルから離す
→ ICM-20948の固定を確認
【問題4】設定を変えても改善しない
→ センサー自体の問題の可能性
→ 別のICM-20948で試す
→ 温度が安定するまで待つ(5-10分)
*/Madgwick AHRS
/*
* Madgwick AHRSアルゴリズム実装ガイド
*
* 従来のComplementary Filterとの比較
*/
// =========================================
// Madgwick AHRSとは?
// =========================================
Madgwick AHRSは、Sebastian Madgwickが開発した
高度な姿勢推定アルゴリズムです。
特徴:
- クォータニオンベース(ジンバルロック回避)
- 9軸センサー融合(加速度+ジャイロ+磁気)
- 計算効率が良い(組み込みに最適)
- ドリフト補正が優秀
// =========================================
// 従来方式との比較
// =========================================
【Complementary Filter】(従来のコード)
✓ シンプル
✓ 軽量
✗ ジンバルロック発生
✗ 長時間でドリフト
✗ 磁気センサーの扱いが単純
【Madgwick AHRS】(新実装)
✓ ジンバルロックなし
✓ 長時間安定
✓ 高精度な磁気補正
✓ 業界標準アルゴリズム
✗ やや複雑
✗ ライブラリが必要
// =========================================
// 必要なライブラリ
// =========================================
Arduino IDEでインストール:
1. Madgwick
ライブラリマネージャで検索: "Madgwick"
作者: Arduino
バージョン: 最新版
インストール手順:
Arduino IDE → ツール → ライブラリを管理
→ "Madgwick" で検索 → インストール
// =========================================
// 主な変更点
// =========================================
1. センサーフュージョンアルゴリズム
Complementary Filter → Madgwick AHRS
2. 姿勢表現
オイラー角 → クォータニオン → オイラー角
3. ジャイロデータ
deg/s → rad/s に変換
4. センサーレンジ
±2g/±250dps → ±16g/±2000dps (広範囲)
5. キャリブレーション
Hard Iron補正のみ → Hard + Soft Iron補正
// =========================================
// パラメータ調整
// =========================================
【1. Sample Frequency(サンプル周波数)】
現在: 50Hz
推奨範囲: 50-200Hz
高い値:
✓ より正確
✗ CPU負荷増
低い値:
✓ 軽い
✗ 精度低下
設定:
const float sampleFreq = 50.0f;
【2. Beta(フィルタゲイン)】
現在: 0.033 (デフォルト)
推奨範囲: 0.01-0.5
小さい値 (0.01-0.05):
✓ 滑らか
✓ ノイズに強い
✗ 収束が遅い
大きい値 (0.1-0.5):
✓ 速い応答
✓ 速い収束
✗ ノイジー
設定:
filter.setBeta(0.1f); // setup()内
// =========================================
// シーン別推奨設定
// =========================================
【シーン1】固定設置、安定性最優先
const float sampleFreq = 50.0f;
filter.setBeta(0.033f); // デフォルト
→ 最も安定、ドリフトほぼゼロ
【シーン2】手持ち、バランス重視
const float sampleFreq = 100.0f;
filter.setBeta(0.05f);
→ 良好なバランス
【シーン3】高速動作、反応速度優先
const float sampleFreq = 200.0f;
filter.setBeta(0.2f);
→ 素早く追従
【シーン4】ドローン・ロボット
const float sampleFreq = 200.0f;
filter.setBeta(0.1f);
→ 高精度制御
// =========================================
// Madgwick vs Mahony
// =========================================
Madgwickの代わりにMahony AHRSも使用可能:
#include <MahonyAHRS.h>
Mahony filter;
特徴:
- Madgwickより軽量
- やや精度は劣る
- パラメータ: Kp, Ki
選択基準:
- 高精度必要 → Madgwick
- 軽量優先 → Mahony
// =========================================
// キャリブレーション
// =========================================
Madgwick版では以下を実行:
1. Hard Iron補正(従来通り)
magOffsetX/Y/Z
2. Soft Iron補正(新機能)
magScaleX/Y/Z
→ 磁場の歪みを補正
実行方法:
ボタン長押し2秒 → 8の字に動かす
// =========================================
// トラブルシューティング
// =========================================
【問題1】コンパイルエラー: Madgwick.h not found
→ Madgwickライブラリをインストール
【問題2】方位がおかしい
→ 磁気センサーのキャリブレーション実行
→ my = -my; の行を確認
【問題3】起動時に姿勢が安定しない
→ 数秒待つ(Madgwickの収束待ち)
→ betaを大きくする(例: 0.1)
【問題4】Roll/Pitchが90度でおかしくなる
→ これはジンバルロック
→ Madgwick版では発生しないはず
→ センサー向きを確認
【問題5】従来版より遅い
→ sampleFreqを下げる(例: 25Hz)
→ delay(20)を調整
// =========================================
// Madgwickアルゴリズムの原理
// =========================================
1. 予測ステップ
ジャイロデータで姿勢を積分
2. 補正ステップ
加速度・磁気センサーで誤差を修正
3. クォータニオン更新
新しい姿勢を計算
4. 正規化
クォータニオンを正規化
詳細:
Open source IMU and AHRS algorithms
// =========================================
// パフォーマンス比較
// =========================================
Complementary | Madgwick
-----------------------------------------------
CPU使用率 低 やや高
メモリ使用 少 やや多
精度 中 高
ドリフト耐性 中 高
ジンバルロック あり なし
磁気補正 簡易 高度
収束時間 速い やや遅い
用途 一般 高精度
// =========================================
// 使用例
// =========================================
// setup()内
filter.begin(50); // 50Hz
filter.setBeta(0.1f); // 高速応答
// loop()内
filter.update(gx, gy, gz, ax, ay, az, mx, my, mz);
float roll = filter.getRoll();
float pitch = filter.getPitch();
float yaw = filter.getYaw();
// =========================================
// 高度な使い方
// =========================================
【1】クォータニオンを直接取得
float q0, q1, q2, q3;
filter.getQuaternion(&q0, &q1, &q2, &q3);
【2】重力ベクトル取得
// 加速度から重力を除去
float grav[3];
filter.getGravity(grav);
【3】線形加速度計算
float linearAx = ax - grav[0];
float linearAy = ay - grav[1];
float linearAz = az - grav[2];
// =========================================
// まとめ
// =========================================
Madgwick AHRSを使用することで:
✓ ジンバルロックなし
✓ 長時間安定
✓ 高精度な姿勢推定
✓ プロフェッショナルな実装
従来のComplementary Filterより優れていますが、
ライブラリのインストールが必要です。
*/C++コード
#include <Wire.h>
#include <SPI.h>
#include <Adafruit_GFX.h>
#include <Adafruit_ST7789.h>
#include <ICM_20948.h>
#include <MadgwickAHRS.h>
#include <math.h>
#define CODE_VERSION "v7.11.0-Madgwick"
// --- Sensor Orientation Configuration ---
#define SENSOR_INVERTED false // true = 裏返し, false = 通常
// --- Pin Settings ---
#define ENC_A_PIN 27
#define ENC_B_PIN 25
#define ENC_SW_PIN 32
#define SDA_PIN 21
#define SCL_PIN 22
// --- ST7789 SPI Settings ---
#define TFT_CS 5
#define TFT_DC 26
#define TFT_RST -1
Adafruit_ST7789 display = Adafruit_ST7789(TFT_CS, TFT_DC, TFT_RST);
ICM_20948_I2C myImu;
// --- Madgwick Filter ---
Madgwick filter;
const float sampleFreq = 50.0f; // 50Hz update rate
// --- Compass Variables ---
float heading = 0.0;
float roll = 0.0;
float pitch = 0.0;
float headingOffset = 0.0;
float rollOffset = 0.0;
float pitchOffset = 0.0;
// --- Timing ---
unsigned long lastUpdateTime = 0;
float dt = 0.0;
// --- Magnetometer Calibration ---
float magOffsetX = 0.0;
float magOffsetY = 0.0;
float magOffsetZ = 0.0;
float magMinX = 0.0, magMaxX = 0.0;
float magMinY = 0.0, magMaxY = 0.0;
float magMinZ = 0.0, magMaxZ = 0.0;
// Magnetometer scale (hard/soft iron correction)
float magScaleX = 1.0;
float magScaleY = 1.0;
float magScaleZ = 1.0;
// --- Button Variables ---
bool buttonPressed = false;
unsigned long buttonPressTime = 0;
unsigned long longPressDuration = 2000;
bool isCalibrating = false;
unsigned long calibrationStartTime = 0;
unsigned long calibrationDuration = 15000;
// --- Previous values for differential update ---
float prevHeading = -999.0;
float prevRoll = -999.0;
float prevPitch = -999.0;
// --- Color Definitions ---
#define COLOR_BG 0x0000
#define COLOR_TEXT 0xFFFF
#define COLOR_HEADING 0x07FF
#define COLOR_ROLL 0xF81F
#define COLOR_PITCH 0xFFE0
#define COLOR_COMPASS 0x07E0
#define COLOR_NEEDLE 0xF800
void setup() {
Serial.begin(115200);
delay(100);
Serial.println("Compass Display " CODE_VERSION);
Serial.println("Using Madgwick AHRS Algorithm");
// --- Button Init ---
pinMode(ENC_SW_PIN, INPUT_PULLUP);
// --- I2C Init ---
Wire.begin(SDA_PIN, SCL_PIN);
Wire.setClock(400000);
// --- Display Init ---
display.init(240, 320);
display.setRotation(0);
display.fillScreen(COLOR_BG);
display.setTextColor(COLOR_TEXT);
display.setTextSize(2);
display.setCursor(20, 140);
display.print("Initializing...");
// --- ICM-20948 Init ---
bool initialized = false;
while (!initialized) {
myImu.begin(Wire, 0); // AD0 = 0
if (myImu.status == ICM_20948_Stat_Ok) {
Serial.println("ICM-20948 initialized successfully");
initialized = true;
} else {
Serial.print("ICM-20948 init failed. Status: ");
Serial.println(myImu.status);
delay(500);
}
}
// Configure ICM-20948 - Use RAW sensor data
ICM_20948_fss_t myFSS;
myFSS.a = gpm16; // Accelerometer: ±16g (high range for Madgwick)
myFSS.g = dps2000; // Gyroscope: ±2000 dps (high range)
myImu.setFullScale(ICM_20948_Internal_Acc | ICM_20948_Internal_Gyr, myFSS);
// Enable magnetometer
myImu.startupMagnetometer();
// --- Initialize Madgwick Filter ---
filter.begin(sampleFreq);
// Madgwick filter gain (beta)
// 小さい値(0.01-0.1): より滑らか、遅い収束
// 大きい値(0.1-0.5): 速い収束、ノイジー
// 推奨: 0.033 (デフォルト) または 0.1 (高速応答)
// filter.setBeta(0.1f); // コメントを外して調整可能
delay(1000);
display.fillScreen(COLOR_BG);
lastUpdateTime = micros();
Serial.println("Madgwick AHRS ready!");
Serial.print("Sample frequency: ");
Serial.print(sampleFreq);
Serial.println(" Hz");
}
void loop() {
handleButton();
if (isCalibrating) {
performCalibration();
return;
}
if (myImu.dataReady()) {
myImu.getAGMT();
// Calculate delta time
unsigned long currentTime = micros();
dt = (currentTime - lastUpdateTime) / 1000000.0f;
lastUpdateTime = currentTime;
// Update orientation using Madgwick
updateMadgwick();
// Display compass
displayCompass();
// Debug output
Serial.print("H:");
Serial.print(heading, 1);
Serial.print("° R:");
Serial.print(roll, 1);
Serial.print("° P:");
Serial.print(pitch, 1);
Serial.println("°");
}
delay(20); // ~50Hz
}
void updateMadgwick() {
// --- Get RAW sensor data ---
float ax = myImu.accX(); // g
float ay = myImu.accY();
float az = myImu.accZ();
float gx = myImu.gyrX(); // deg/s
float gy = myImu.gyrY();
float gz = myImu.gyrZ();
float mx = myImu.magX(); // µT
float my = myImu.magY();
float mz = myImu.magZ();
// --- Apply sensor orientation correction ---
#if SENSOR_INVERTED
ax = -ax;
az = -az;
gx = -gx;
gz = -gz;
mx = -mx;
mz = -mz;
#endif
// --- Apply magnetometer calibration ---
mx = (mx - magOffsetX) * magScaleX;
my = (my - magOffsetY) * magScaleY;
mz = (mz - magOffsetZ) * magScaleZ;
// 180度補正が必要な場合
my = -my;
// --- Convert gyro from deg/s to rad/s for Madgwick ---
gx = gx * DEG_TO_RAD;
gy = gy * DEG_TO_RAD;
gz = gz * DEG_TO_RAD;
// --- Update Madgwick filter ---
// Madgwick expects: gx, gy, gz (rad/s), ax, ay, az (any unit), mx, my, mz (any unit)
filter.update(gx, gy, gz, ax, ay, az, mx, my, mz);
// --- Get orientation from quaternion ---
// Roll, Pitch, Yaw in degrees
roll = filter.getRoll() - rollOffset;
pitch = filter.getPitch() - pitchOffset;
float yaw = filter.getYaw();
// Convert yaw to heading (0-360)
heading = yaw - headingOffset;
if (heading < 0) heading += 360.0f;
if (heading >= 360.0f) heading -= 360.0f;
}
void displayCompass() {
float headingDiff = abs(heading - prevHeading);
float rollDiff = abs(roll - prevRoll);
float pitchDiff = abs(pitch - prevPitch);
bool fullRedraw = (prevHeading < -900 || headingDiff > 180 || headingDiff > 5 || rollDiff > 2 || pitchDiff > 2);
if (fullRedraw) {
display.fillScreen(COLOR_BG);
drawCompassBackground();
}
drawCompassNeedle();
drawHeadingInfo();
drawAttitudeBars();
prevHeading = heading;
prevRoll = roll;
prevPitch = pitch;
}
void drawCompassBackground() {
int centerX = 120;
int centerY = 160;
int radius = 100;
display.drawCircle(centerX, centerY, radius, COLOR_COMPASS);
display.drawCircle(centerX, centerY, radius - 1, COLOR_COMPASS);
display.drawCircle(centerX, centerY, radius - 2, COLOR_COMPASS);
display.drawCircle(centerX, centerY, radius - 15, COLOR_TEXT);
for (int i = 0; i < 360; i += 30) {
float angle = (i - 90) * M_PI / 180.0;
int x1 = centerX + (radius - 10) * cos(angle);
int y1 = centerY + (radius - 10) * sin(angle);
int x2 = centerX + (radius - 3) * cos(angle);
int y2 = centerY + (radius - 3) * sin(angle);
if (i % 90 == 0) {
display.drawLine(x1, y1, x2, y2, COLOR_TEXT);
display.drawLine(x1 + 1, y1, x2 + 1, y2, COLOR_TEXT);
} else {
x1 = centerX + (radius - 6) * cos(angle);
display.drawLine(x1, y1, x2, y2, COLOR_TEXT);
}
}
display.setTextSize(3);
display.setTextColor(COLOR_TEXT);
display.setCursor(centerX - 12, centerY - radius + 20);
display.print("N");
display.setCursor(centerX + radius - 35, centerY - 12);
display.print("E");
display.setCursor(centerX - 10, centerY + radius - 45);
display.print("S");
display.setCursor(centerX - radius + 15, centerY - 12);
display.print("W");
}
void drawCompassNeedle() {
int centerX = 120;
int centerY = 160;
int radius = 100;
display.fillCircle(centerX, centerY, radius - 17, COLOR_BG);
float headingRad = (heading - 90) * M_PI / 180.0;
int needleLength = radius - 20;
int needleX = centerX + needleLength * cos(headingRad);
int needleY = centerY + needleLength * sin(headingRad);
for (int i = -2; i <= 2; i++) {
float perpAngle = headingRad + M_PI / 2;
int offsetX = i * cos(perpAngle);
int offsetY = i * sin(perpAngle);
display.drawLine(centerX + offsetX, centerY + offsetY, needleX + offsetX, needleY + offsetY, COLOR_NEEDLE);
}
float arrowAngle1 = headingRad - 2.8;
float arrowAngle2 = headingRad + 2.8;
int arrowX1 = needleX - 15 * cos(arrowAngle1);
int arrowY1 = needleY - 15 * sin(arrowAngle1);
int arrowX2 = needleX - 15 * cos(arrowAngle2);
int arrowY2 = needleY - 15 * sin(arrowAngle2);
display.fillTriangle(needleX, needleY, arrowX1, arrowY1, arrowX2, arrowY2, COLOR_NEEDLE);
int southLength = radius - 30;
float southAngle = headingRad + M_PI;
int southX = centerX + southLength * cos(southAngle);
int southY = centerY + southLength * sin(southAngle);
display.drawLine(centerX, centerY, southX, southY, COLOR_TEXT);
display.drawLine(centerX + 1, centerY, southX + 1, southY, COLOR_TEXT);
display.fillCircle(centerX, centerY, 6, COLOR_NEEDLE);
display.drawCircle(centerX, centerY, 7, COLOR_TEXT);
}
void drawHeadingInfo() {
display.fillRect(0, 0, 240, 70, COLOR_BG);
display.setTextSize(3);
display.setTextColor(COLOR_HEADING);
display.setCursor(95, 10);
display.print(getDirectionString(heading));
display.setTextSize(2);
display.setCursor(80, 40);
display.print((int)heading);
display.print("deg");
}
void drawAttitudeBars() {
display.fillRect(0, 295, 240, 25, COLOR_BG);
display.setTextSize(1);
display.setCursor(10, 300);
display.setTextColor(COLOR_ROLL);
display.print("R:");
display.print((int)roll);
display.print("deg");
int rollBarX = 80;
int rollBarY = 300;
int rollBarWidth = 140;
int rollPos = map(constrain(roll, -90, 90), -90, 90, 0, rollBarWidth);
display.drawRect(rollBarX, rollBarY, rollBarWidth, 8, COLOR_TEXT);
display.fillRect(rollBarX + rollBarWidth/2 - 1, rollBarY, 2, 8, COLOR_TEXT);
display.fillRect(rollBarX + rollPos - 2, rollBarY + 1, 4, 6, COLOR_ROLL);
display.setCursor(10, 312);
display.setTextColor(COLOR_PITCH);
display.print("P:");
display.print((int)pitch);
display.print("deg");
int pitchBarX = 80;
int pitchBarY = 312;
int pitchBarWidth = 140;
int pitchPos = map(constrain(pitch, -90, 90), -90, 90, 0, pitchBarWidth);
display.drawRect(pitchBarX, pitchBarY, pitchBarWidth, 8, COLOR_TEXT);
display.fillRect(pitchBarX + pitchBarWidth/2 - 1, pitchBarY, 2, 8, COLOR_TEXT);
display.fillRect(pitchBarX + pitchPos - 2, pitchBarY + 1, 4, 6, COLOR_PITCH);
}
String getDirectionString(float hdg) {
if (hdg >= 337.5 || hdg < 22.5) return "N";
else if (hdg >= 22.5 && hdg < 67.5) return "NE";
else if (hdg >= 67.5 && hdg < 112.5) return "E";
else if (hdg >= 112.5 && hdg < 157.5) return "SE";
else if (hdg >= 157.5 && hdg < 202.5) return "S";
else if (hdg >= 202.5 && hdg < 247.5) return "SW";
else if (hdg >= 247.5 && hdg < 292.5) return "W";
else if (hdg >= 292.5 && hdg < 337.5) return "NW";
return "?";
}
void handleButton() {
bool currentState = digitalRead(ENC_SW_PIN) == LOW;
if (currentState && !buttonPressed) {
buttonPressed = true;
buttonPressTime = millis();
}
else if (!currentState && buttonPressed) {
unsigned long pressDuration = millis() - buttonPressTime;
if (pressDuration >= longPressDuration) {
startCalibration();
} else {
zeroHeading();
}
buttonPressed = false;
}
}
void zeroHeading() {
// Get current orientation from Madgwick
headingOffset = filter.getYaw();
rollOffset = filter.getRoll();
pitchOffset = filter.getPitch();
Serial.print("Zeroed! H:");
Serial.print(headingOffset);
Serial.print("° R:");
Serial.print(rollOffset);
Serial.print("° P:");
Serial.print(pitchOffset);
Serial.println("°");
display.fillRect(60, 150, 120, 40, COLOR_BG);
display.setTextSize(2);
display.setTextColor(COLOR_HEADING);
display.setCursor(70, 160);
display.print("ZEROED!");
delay(1000);
prevHeading = -999.0;
}
void startCalibration() {
isCalibrating = true;
calibrationStartTime = millis();
magMinX = magMaxX = myImu.magX();
magMinY = magMaxY = myImu.magY();
magMinZ = magMaxZ = myImu.magZ();
Serial.println("Magnetometer calibration started!");
Serial.println("Move sensor in figure-8 pattern...");
display.fillScreen(COLOR_BG);
display.setTextSize(2);
display.setTextColor(COLOR_HEADING);
display.setCursor(20, 100);
display.print("CALIBRATING");
display.setTextSize(1);
display.setCursor(20, 140);
display.print("Move sensor in");
display.setCursor(20, 160);
display.print("figure-8 pattern");
}
void performCalibration() {
myImu.getAGMT();
float mx = myImu.magX();
float my = myImu.magY();
float mz = myImu.magZ();
if (mx < magMinX) magMinX = mx;
if (mx > magMaxX) magMaxX = mx;
if (my < magMinY) magMinY = my;
if (my > magMaxY) magMaxY = my;
if (mz < magMinZ) magMinZ = mz;
if (mz > magMaxZ) magMaxZ = mz;
unsigned long elapsed = millis() - calibrationStartTime;
unsigned long remaining = calibrationDuration - elapsed;
if (elapsed % 500 < 100) {
display.fillRect(20, 200, 200, 60, COLOR_BG);
display.setTextSize(2);
display.setTextColor(COLOR_TEXT);
display.setCursor(40, 210);
display.print("Time: ");
display.print(remaining / 1000);
display.print("s");
int barWidth = 200;
int progress = (elapsed * barWidth) / calibrationDuration;
display.drawRect(20, 240, barWidth, 20, COLOR_TEXT);
display.fillRect(22, 242, progress - 4, 16, COLOR_HEADING);
}
if (elapsed >= calibrationDuration) {
finishCalibration();
}
delay(10);
}
void finishCalibration() {
// Hard iron correction (offset)
magOffsetX = (magMaxX + magMinX) / 2.0f;
magOffsetY = (magMaxY + magMinY) / 2.0f;
magOffsetZ = (magMaxZ + magMinZ) / 2.0f;
// Soft iron correction (scale)
float rangeX = magMaxX - magMinX;
float rangeY = magMaxY - magMinY;
float rangeZ = magMaxZ - magMinZ;
float avgRange = (rangeX + rangeY + rangeZ) / 3.0f;
magScaleX = avgRange / rangeX;
magScaleY = avgRange / rangeY;
magScaleZ = avgRange / rangeZ;
isCalibrating = false;
Serial.println("Magnetometer calibration complete!");
Serial.println("Hard Iron Offsets:");
Serial.print(" X: "); Serial.println(magOffsetX);
Serial.print(" Y: "); Serial.println(magOffsetY);
Serial.print(" Z: "); Serial.println(magOffsetZ);
Serial.println("Soft Iron Scales:");
Serial.print(" X: "); Serial.println(magScaleX);
Serial.print(" Y: "); Serial.println(magScaleY);
Serial.print(" Z: "); Serial.println(magScaleZ);
display.fillScreen(COLOR_BG);
display.setTextSize(2);
display.setTextColor(COLOR_HEADING);
display.setCursor(20, 100);
display.print("COMPLETE!");
display.setTextSize(1);
display.setTextColor(COLOR_TEXT);
display.setCursor(20, 140);
display.print("Offsets:");
display.setCursor(20, 160);
display.print("X:"); display.print(magOffsetX, 1);
display.setCursor(20, 175);
display.print("Y:"); display.print(magOffsetY, 1);
display.setCursor(20, 190);
display.print("Z:"); display.print(magOffsetZ, 1);
delay(3000);
display.fillScreen(COLOR_BG);
prevHeading = -999.0;
}