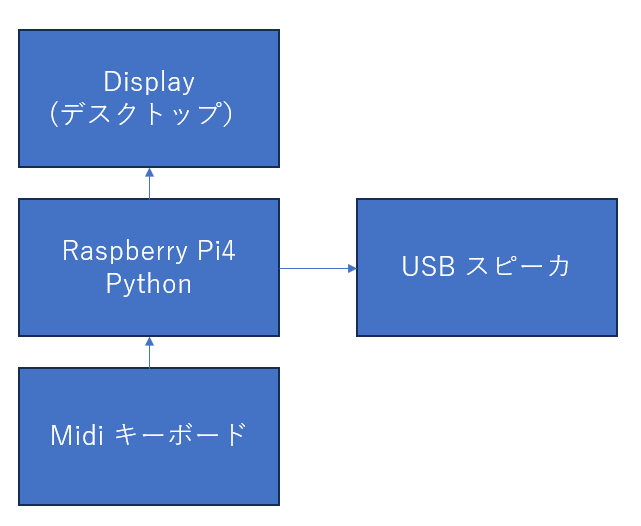
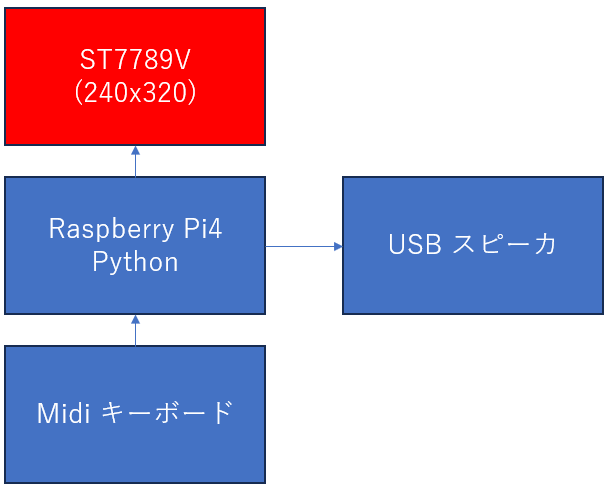
Raspberry Pi Pico 2 (RP2350) とタッチパネル液晶、そしてUSB MIDIキーボードを組み合わせた自作シンセサイザー開発における、デバッグの記録を記事にまとめました。
【RP2350】Pico 2でタッチパネル液晶シンセを作る:CST328の座標ズレとUSB Host MIDI認識エラーとの闘い
背景
Raspberry Pi Pico 2 (RP2350) に Waveshareの2.8インチタッチLCDを接続し、ポリフォニック・シンセサイザーを作成していました。
音の生成やSDカードからのMIDIファイル再生までは順調でしたが、「タッチパネルの座標が正しく取れない」 問題と、「USB MIDIキーボードを接続しても認識しない(USBホスト機能)」 という2つの大きな壁にぶつかりました。
この記事は、その解決までの試行錯誤のログです。
エラーとの戦い:試行錯誤のプロセス
Round 1: タッチ座標がノコギリ波になる
最初に書いたコードでは、タッチコントローラー(CST328)からI2Cで単純に座標バイトを読み込んでいました。
Step 1: 最初のコード(抜粋)
C++
// よくあるI2C読み込み
Wire1.requestFrom(CST_ADDR, 4);
uint8_t x_h = Wire1.read();
uint8_t x_l = Wire1.read();
// ... 単純結合 ...
Step 2: 発生した現象
エラーメッセージは出ませんでしたが、シリアルモニタで座標を見ると以下の挙動を示しました。
- 横方向(X軸)に指を動かすと、値が
0 -> 300 -> 1 ...のようにループする(ノコギリ波状)。 - 画面の右に行くほど値が減る(逆転している)。
Step 3: 原因の解説
WaveshareのPythonサンプルコードを確認したところ、このタッチパネルは 12ビットのデータを変則的にパッキングして送信 しており、しかもレジスタアドレスが8bitではなく 16bit (0xD000) でアクセスする必要がありました。単純なバイト読み込みでは、上位ビットと下位ビットが正しく結合されていませんでした。
Step 4: 修正したコード(ビット演算の修正)
C++
// レジスタポインタを0xD000にセット
Wire1.beginTransmission(CST_ADDR);
Wire1.write(0xD0);
Wire1.write(0x00);
Wire1.endTransmission(false); // Repeated Start
// 変則的な12bitデコード(Pythonコードを移植)
// buf[3]にXとYの下位4ビットが混ざっている
int raw_x = ((int)buf[1] << 4) | ((buf[3] & 0xF0) >> 4);
int raw_y = ((int)buf[2] << 4) | (buf[3] & 0x0F);
Round 2: ボタンが連打されてしまう(ゴーストタッチ)
座標は取れるようになりましたが、画面上の「NEXT」ボタンを一回押したつもりが、ページが2つ3つ進んでしまう現象が発生しました。
Step 1: 問題のコード
C++
// タッチされた瞬間だけ反応するつもりだったが...
if (touch.touched) {
// 処理
}
Step 2: 発生した現象
指を離しても、タッチパネルのレジスタに「最後の座標」が残り続け、プログラムが「まだ押されている」と誤認して処理をループさせていました。
Step 3: 修正案
「静止画検知(ジッターフィルタ)」と「リリース待ちフラグ」を導入しました。
- 静止検知: 人間の指は微妙に震えるため、座標が完全に一致し続ける場合は「指がない(レジスタのゴミ)」と判定して無視。
- リリース待ち: ボタンを押した後、一度指を離す(
!touchedになる)まで次の入力を受け付けないようにしました。
Round 3: MIDIコールバック関数のコンパイルエラー
次に、USB MIDIキーボードを接続するためのコードを追加したところでコンパイルエラーが発生しました。
Step 1: 追加したコード
C++
// 古いライブラリ仕様に基づいた記述
void tuh_midi_mount_cb(uint8_t d, uint8_t in_ep, uint16_t in_packet_size, uint8_t out_ep, uint16_t out_packet_size, void *ptr) {
// ...
}
Step 2: 発生したエラー
Plaintext
error: conflicting declaration of C function 'void tuh_midi_mount_cb(...)'
note: previous declaration 'void tuh_midi_mount_cb(uint8_t, const tuh_midi_mount_cb_t*)'
Step 3: 原因の解説
使用している Adafruit TinyUSB ライブラリのバージョンが上がり、コールバック関数の引数の仕様が変わっていました。エラーログの note に正解が書いてありました。
Step 4: 修正したコード
C++
// 最新の仕様に合わせた引数
void tuh_midi_mount_cb(uint8_t idx, const tuh_midi_mount_cb_t *mount_cb_data) {
usb_mounted = true;
}
Round 4: MIDIキーボードを認識しない(最大の山場)
コンパイルは通りましたが、Pico 2 WにUSBキーボードを繋いでも全く反応しません(Lチカによるデバッグでも反応なし)。しかし、単純なサンプルコードでは動作しました。
Step 1: 失敗していた構成
- Arduino IDE設定:
USB Stack: Adafruit TinyUSB - コード:
USBDevice.attach()(PC接続用)とUSBHost.begin(0)(キーボード接続用)を混在させていた。 - コード:
Serial1(ハードウェアMIDI) を初期化していた。
Step 2: 発生した現象
プログラムは起動するが、USBポートにキーボードを挿しても tuh_midi_mount_cb が呼ばれない。
Step 3: 原因の解説
Pico 2 (RP2350) でUSBホスト機能を使う場合、以下の条件が必須でした。
- IDEの設定: メニューの「USB Stack」で “Adafruit TinyUSB (Host)” を明示的に選ぶ必要がある(無印のTinyUSBではデバイスモードが優先されるためNG)。
- 初期化順序:
USBHost.begin(0)をsetup()の一番最初に呼ぶ必要がある。
Step 4: 最終的な修正
IDEの設定を “Adafruit TinyUSB (Host)” に変更し、コードもUSBホスト専用に特化させました。
完成コード
これら全ての問題を解決し、タッチ操作とUSB MIDIキーボード演奏が両立した最終コードです。
<details>
<summary>クリックしてコードを展開: PolySynth_RP2350_LCD2_Touch_v16_00.ino</summary>
C++
// PolySynth_RP2350_LCD2_Touch_v16_00
// Target: Raspberry Pi Pico 2 / Pico 2 W (RP2350)
// REQUIRED IDE SETTING: Tools > USB Stack > "Adafruit TinyUSB (Host)"
//
// Fixes:
// 1. Validated for "TinyUSB (Host)" build option.
// 2. P4 (Visualizer) Touch Fix: Touch is polled continuously, independent of FFT framerate.
// 3. MIDI: Host Mode only.
#define ENABLE_TOUCH
#include <Arduino.h>
#include <I2S.h>
#include <SPI.h>
#include <Adafruit_GFX.h>
#include <Adafruit_ST7789.h>
#include <Adafruit_TinyUSB.h> // ★ Must use "Adafruit TinyUSB (Host)" setting
#include <Wire.h>
#include "hardware/watchdog.h"
#include <LittleFS.h>
#include "arduinoFFT.h"
#include "hardware/vreg.h"
#include "hardware/clocks.h"
const char* VERSION_STR = "v16.00 (Host/P4Fix)";
// --- Configuration ---
#define SAMPLE_RATE 44100
#define POLYPHONY 14
#define SINE_SIZE 1024
#define AUDIO_BLOCK 64
#define FFT_SAMPLES 512
#define SCOPE_SAMPLES 320
#define MAX_MIDI_FILES 20
#define MAX_TRACKS 16
#define MAX_PAGES 6
#define DELAY_LEN 16537
#define COMB1_LEN 1601
#define COMB2_LEN 1811
#define AP_LEN 499
// --- Colors ---
#define C_BLACK 0x0000
#define C_WHITE 0xFFFF
#define C_CYAN 0x07FF
#define C_MAGENTA 0xF81F
#define C_ORANGE 0xFD20
#define C_GREEN 0x07E0
#define C_YELLOW 0xFFE0
#define C_RED 0xF800
#define C_GRAY 0x4208
#define C_DARK 0x1082
#define C_BLUE 0x001F
// --- Pins ---
#define TFT_BL 16
#define TFT_DC 14
#define TFT_CS 13
#define TFT_SCLK 10
#define TFT_MOSI 11
#define TFT_RST 15
#define TOUCH_SDA 6
#define TOUCH_SCL 7
#define TOUCH_RST 17
#define I2S_BCLK 2
#define I2S_DOUT 4
#define CST_ADDR 0x1A
// --- USB Objects ---
Adafruit_USBH_Host USBHost;
volatile bool midi_active = false;
// --- Prototypes ---
void triggerNoteOn(uint8_t note, uint8_t velocity, bool is_drum);
void triggerNoteOff(uint8_t note, bool is_drum);
void apply_selection(int idx);
class CST328 {
public:
int x = 0, y = 0;
int raw_x = 0, raw_y = 0;
bool touched = false;
int last_raw_x = -1, last_raw_y = -1;
int static_count = 0;
void begin() {
Wire1.setSDA(TOUCH_SDA);
Wire1.setSCL(TOUCH_SCL);
Wire1.begin();
Wire1.setClock(400000);
pinMode(TOUCH_RST, OUTPUT);
digitalWrite(TOUCH_RST, HIGH); delay(50);
digitalWrite(TOUCH_RST, LOW); delay(20);
digitalWrite(TOUCH_RST, HIGH); delay(100);
}
bool read() {
Wire1.beginTransmission(CST_ADDR);
Wire1.write(0x01);
if (Wire1.endTransmission() != 0) return false;
Wire1.requestFrom(CST_ADDR, 6);
if (Wire1.available() < 6) return false;
uint8_t buf[6];
for(int i=0; i<6; i++) buf[i] = Wire1.read();
int val_A = ((uint16_t)buf[0] << 4) | ((buf[2] & 0xF0) >> 4);
int val_B = ((uint16_t)buf[1] << 4) | (buf[2] & 0x0F);
bool valid_read = (val_A > 0 || val_B > 0);
if (valid_read) {
if (val_A == last_raw_y && val_B == last_raw_x) {
static_count++;
} else {
static_count = 0;
}
last_raw_y = val_A;
last_raw_x = val_B;
if (static_count > 20) {
touched = false;
} else {
touched = true;
raw_y = val_A;
raw_x = val_B;
// Calibration (Proven)
x = map(raw_x, 317, 1, 0, 320);
y = map(raw_y, 1, 239, 0, 240);
if (x < 0) x = 0; if (x > 320) x = 320;
if (y < 0) y = 0; if (y > 240) y = 240;
}
} else {
touched = false;
static_count = 0;
}
return touched;
}
} touch;
// --- Globals ---
const char* ALL_NAMES[] = {"SINE", "SAW", "TRI", "SQR", "NOISE", "PIANO", "ORGAN", "VIOLIN", "MBOX", "SEA", "WIND"};
const uint8_t total_presets = 11;
struct Voice {
int note = -1; float freq = 0, target_freq = 0, ph = 0, mod_ph = 0, env = 0;
int stage = 0; bool active = false; bool is_drum = false;
float low = 0, band = 0, f_coeff = 0;
};
struct MidiTrackState {
uint32_t start_offset; uint32_t cursor; uint32_t next_tick; uint8_t running_st; bool active;
};
struct {
volatile int page = 0, wave = 0, preset = 0, selected_file_idx = 0;
int total_files = 0;
volatile float gain = 0.8f, lfo_f = 0.2f, lfo_d = 0.0f, lfo_ph = 0;
volatile float a=0.01f, d=0.2f, s=0.6f, r=0.5f, cut=8000.0f, res=0.1f;
volatile float glide = 0.0f, fm_idx = 0.0f, chorus = 0.0f;
volatile float delay_mix = 0.0f; volatile float reverb_mix = 0.0f;
volatile float play_speed = 1.0f;
volatile bool playing = false, dirty = true;
volatile bool note_active = false;
uint32_t current_tick = 0; uint32_t us_per_tick = 1000;
volatile bool req_file_reload = false; volatile bool req_panic = false;
} p;
Voice voices[POLYPHONY];
float sineTbl[SINE_SIZE];
MidiTrackState tracks[MAX_TRACKS];
int num_tracks_active = 0;
float delayBuf[DELAY_LEN]; int delay_idx = 0;
float comb1Buf[COMB1_LEN]; int c1_idx = 0;
float comb2Buf[COMB2_LEN]; int c2_idx = 0;
float apBuf[AP_LEN]; int ap_idx = 0;
volatile int16_t scope_buf[SCOPE_SAMPLES];
float vReal[FFT_SAMPLES], vImag[FFT_SAMPLES];
volatile bool fft_ready = false;
volatile int s_ptr = 0; volatile int f_ptr = 0;
int last_touch_note = -1;
uint32_t last_btn_action = 0;
bool finger_released = true;
I2S i2s(OUTPUT);
Adafruit_ST7789 tft = Adafruit_ST7789(&SPI1, TFT_CS, TFT_DC, TFT_RST);
ArduinoFFT<float> FFT = ArduinoFFT<float>(vReal, vImag, FFT_SAMPLES, SAMPLE_RATE);
// --- File System ---
char midi_filenames[MAX_MIDI_FILES][32];
File midiFile;
String formatMidiName(const char* name) {
String s = String(name); s.replace(".mid", ""); s.replace(".MID", "");
if(s.length() > 12) s = s.substring(0, 12);
return s;
}
void scanMidiFiles() {
p.total_files = 0;
Dir dir = LittleFS.openDir("/midi");
if (!dir.next()) dir = LittleFS.openDir("/");
dir.rewind();
while (dir.next() && p.total_files < MAX_MIDI_FILES) {
String n = dir.fileName();
if (n.endsWith(".mid") || n.endsWith(".MID")) {
strncpy(midi_filenames[p.total_files], n.c_str(), 31);
p.total_files++;
}
}
p.dirty = true;
}
uint32_t xorshift32() {
static uint32_t x = 123456789;
x ^= x << 13; x ^= x >> 17; x ^= x << 5;
return x;
}
// --- SOUND ENGINE ---
void triggerNoteOn(uint8_t note, uint8_t velocity, bool is_drum) {
float tf = 440.0f * powf(2.0f, (note - 69.0f) / 12.0f);
for(int i=0; i<POLYPHONY; i++) {
if(voices[i].active && voices[i].note == note && voices[i].is_drum == is_drum) voices[i].active = false;
}
for(int i=0; i<POLYPHONY; i++) if(!voices[i].active) {
voices[i].note = note; voices[i].target_freq = tf;
if(p.glide == 0 || is_drum) voices[i].freq = tf;
if(p.glide > 0 && !is_drum) voices[i].freq = tf;
voices[i].ph = 0; voices[i].stage = 1; voices[i].env = 0;
voices[i].active = true; voices[i].low = 0; voices[i].band = 0;
voices[i].is_drum = is_drum;
p.note_active = true; break;
}
}
void triggerNoteOff(uint8_t note, bool is_drum) {
bool any_active = false;
for(int i=0; i<POLYPHONY; i++) {
if(voices[i].note == note && voices[i].active && voices[i].is_drum == is_drum) voices[i].stage = 4;
if(voices[i].active && voices[i].stage != 4) any_active = true;
}
p.note_active = any_active;
}
void panic() {
for(int i=0; i<POLYPHONY; i++) {
voices[i].active = false; voices[i].env = 0.0f; voices[i].stage = 0;
}
p.note_active = false;
}
// --- SEQUENCER ---
uint32_t readVarLen() {
uint32_t val = 0; uint8_t c;
do { c = midiFile.read(); val = (val << 7) | (c & 0x7F); } while (c & 0x80);
return val;
}
void init_sequencer() {
if (midiFile) midiFile.close();
if (p.total_files == 0) { p.playing = false; p.dirty = true; return; }
String path = "/midi/"; path += midi_filenames[p.selected_file_idx];
midiFile = LittleFS.open(path, "r");
if (!midiFile) midiFile = LittleFS.open("/" + String(midi_filenames[p.selected_file_idx]), "r");
if (!midiFile) { p.playing = false; p.dirty = true; return; }
midiFile.seek(0); char chunk[4]; midiFile.readBytes(chunk, 4);
if (strncmp(chunk, "MThd", 4) != 0) { p.playing = false; p.dirty = true; return; }
midiFile.seek(10); uint16_t numTrks; midiFile.readBytes((char*)&numTrks, 2); numTrks = __builtin_bswap16(numTrks);
uint16_t timeDiv; midiFile.readBytes((char*)&timeDiv, 2); timeDiv = __builtin_bswap16(timeDiv);
p.us_per_tick = 500000 / timeDiv;
num_tracks_active = 0; midiFile.seek(14);
while(midiFile.available() && num_tracks_active < MAX_TRACKS && num_tracks_active < numTrks) {
uint32_t chunkStart = midiFile.position(); midiFile.readBytes(chunk, 4);
uint32_t len; midiFile.readBytes((char*)&len, 4); len = __builtin_bswap32(len);
if (strncmp(chunk, "MTrk", 4) == 0) {
tracks[num_tracks_active].start_offset = midiFile.position();
tracks[num_tracks_active].cursor = midiFile.position();
tracks[num_tracks_active].active = true;
tracks[num_tracks_active].running_st = 0;
tracks[num_tracks_active].next_tick = readVarLen();
tracks[num_tracks_active].cursor = midiFile.position();
num_tracks_active++;
}
midiFile.seek(chunkStart + 8 + len);
}
p.current_tick = 0;
}
void update_sequencer() {
if (!p.playing) return;
if (!midiFile) { init_sequencer(); if(!p.playing) return; }
static uint32_t last_time = 0;
if (micros() - last_time < (uint32_t)(p.us_per_tick / p.play_speed)) return;
last_time = micros();
p.current_tick++;
bool any_active = false;
for (int i = 0; i < num_tracks_active; i++) {
if (!tracks[i].active) continue;
any_active = true;
while (tracks[i].next_tick <= p.current_tick) {
midiFile.seek(tracks[i].cursor);
uint8_t b = midiFile.read();
if (b >= 0x80) { tracks[i].running_st = b; b = midiFile.read(); }
uint8_t status = tracks[i].running_st;
uint8_t type = status & 0xF0;
if (type == 0xF0) {
if (status == 0xFF) {
uint8_t metaType = b; uint32_t len = readVarLen();
if (metaType == 0x2F) tracks[i].active = false; else midiFile.seek(midiFile.position() + len);
} else if (status == 0xF0 || status == 0xF7) { uint32_t len = readVarLen(); midiFile.seek(midiFile.position() + len); }
} else {
uint8_t d1 = b; uint8_t d2 = 0; if (type != 0xC0 && type != 0xD0) d2 = midiFile.read();
uint8_t ch = status & 0x0F; bool is_drum = (ch == 9);
if (type == 0x90 && d2 > 0) triggerNoteOn(d1, d2, is_drum);
else if (type == 0x80 || (type == 0x90 && d2 == 0)) triggerNoteOff(d1, is_drum);
}
if (tracks[i].active) { tracks[i].next_tick += readVarLen(); tracks[i].cursor = midiFile.position(); } else { break; }
}
}
if (!any_active) { p.playing = false; p.req_panic = true; p.dirty = true; }
}
void apply_selection(int idx) {
p.preset = constrain(idx, 0, (int)total_presets - 1);
p.delay_mix = 0.0f; p.reverb_mix = 0.0f;
if (p.preset < 5) {
p.wave = p.preset; p.a=0.01; p.d=0.3; p.s=0.8; p.r=0.3; p.cut=8000.0f; p.res=0.1f; p.lfo_d=0.0f; p.glide=0.0f;
} else {
switch(p.preset) {
case 5: p.wave=1; p.a=0.01; p.d=0.5; p.s=0.0; p.r=0.4; p.cut=2800; p.res=0.1; break;
case 6: p.wave=3; p.a=0.02; p.d=0.1; p.s=1.0; p.r=0.1; p.cut=4500; p.res=0.0; break;
case 7: p.wave=1; p.a=0.30; p.d=0.3; p.s=0.7; p.r=0.6; p.cut=2200; p.res=0.3; p.lfo_f=0.3; p.lfo_d=0.3; p.glide=0.06; break;
case 8: p.wave=0; p.a=0.01; p.d=1.5; p.s=0.0; p.r=1.0; p.cut=3500; p.res=0.2; break;
case 9: p.wave=4; p.a=2.5; p.d=2.0; p.s=0.4; p.r=2.5; p.cut=600; p.res=0.1; break;
case 10: p.wave=4; p.a=1.5; p.d=1.5; p.s=0.5; p.r=2.0; p.cut=1000; p.res=0.88; break;
}
}
if (p.preset == 7) p.reverb_mix = 0.3f;
if (p.preset == 9) p.delay_mix = 0.4f;
p.dirty = true;
}
// UI
void drawCell(int col, int row, const char* label, String valStr, float val, float maxVal, uint16_t color) {
int x = (col == 0) ? 5 : 165; int y = 35 + row * 50; int w = 150;
tft.setTextColor(C_YELLOW, C_BLACK); tft.setTextSize(1);
tft.setCursor(x, y); tft.print("K"); tft.print(col == 0 ? row + 1 : row + 5); tft.print(" "); tft.print(label);
tft.setTextColor(C_WHITE, C_BLACK); tft.setTextSize(2);
tft.setCursor(x, y + 12); tft.print(valStr);
int barY = y + 36;
if (maxVal <= 1.0f) { // Toggle
uint16_t btnColor = (val > 0.5f) ? color : C_DARK;
tft.fillRect(x, barY - 4, w, 14, btnColor);
tft.drawRect(x, barY - 4, w, 14, C_WHITE);
} else { // Slider
tft.drawRect(x, barY, w, 6, C_GRAY);
int fillW = constrain((int)((val / maxVal) * (w - 2)), 0, w - 2);
tft.fillRect(x + 1, barY + 1, fillW, 4, color);
}
}
void drawKeyboard() {
int wk_w = 40; int bk_w = 26; int bk_h = 130;
int y_start = 40; int h = 200;
for(int i=0; i<8; i++) {
tft.fillRect(i*wk_w, y_start, wk_w-1, h, C_WHITE);
tft.drawRect(i*wk_w, y_start, wk_w-1, h, C_GRAY);
}
int bk_pos[] = {1, 2, 4, 5, 6};
for(int i=0; i<5; i++) {
int cx = bk_pos[i] * wk_w;
tft.fillRect(cx - (bk_w/2), y_start, bk_w, bk_h, C_BLACK);
}
tft.setTextColor(C_BLACK); tft.setTextSize(1);
tft.setCursor(12, 220); tft.print("C4"); tft.setCursor(292, 220); tft.print("C5");
}
void drawSystemPage() {
tft.setTextColor(C_WHITE, C_BLACK);
tft.setCursor(10, 40); tft.setTextSize(2); tft.print("SYSTEM MENU");
tft.setCursor(10, 70); tft.setTextSize(1); tft.setTextColor(C_GRAY); tft.print("USB MODE:");
tft.setCursor(160, 70); tft.setTextColor(C_GREEN); tft.print("HOST (KEYS)");
// Version Display
tft.setCursor(80, 210); tft.setTextSize(1); tft.setTextColor(C_GRAY);
tft.print("FIRMWARE: "); tft.print(VERSION_STR);
}
void handle_touch() {
touch.read();
if (!touch.touched) {
if (last_touch_note != -1) { triggerNoteOff(last_touch_note, false); last_touch_note = -1; }
finger_released = true;
return;
}
int tx = touch.x; int ty = touch.y;
if (tx == 0 && ty == 0) return;
bool can_trigger_btn = (millis() - last_btn_action > 300);
if (ty < 50 && tx > 200) { // Global Nav
if (finger_released) {
p.page = (p.page + 1) % MAX_PAGES;
if(p.page >= MAX_PAGES) p.page = 0;
p.dirty = true; finger_released = false;
if (last_touch_note != -1) { triggerNoteOff(last_touch_note, false); last_touch_note = -1; }
}
return;
}
if (p.page == 4) { // Keyboard
if (tx < 0 || tx > 320 || ty < 40) return;
int wk_w = 40; int bk_w = 26; int bk_h = 130 + 40;
int base_note = 60; int note = -1;
int bk_centers[] = {40, 80, 160, 200, 240}; int bk_notes[] = {1, 3, 6, 8, 10};
bool is_black = false;
if (ty < bk_h) {
for(int i=0; i<5; i++) {
if (tx >= (bk_centers[i] - bk_w/2) && tx <= (bk_centers[i] + bk_w/2)) {
note = base_note + bk_notes[i]; is_black = true; break;
}
}
}
if (!is_black) {
int wk_idx = tx / wk_w; int wk_notes[] = {0, 2, 4, 5, 7, 9, 11, 12};
if(wk_idx >= 0 && wk_idx < 8) note = base_note + wk_notes[wk_idx];
}
if (note != last_touch_note) {
if (last_touch_note != -1) triggerNoteOff(last_touch_note, false);
if (note != -1) triggerNoteOn(note, 100, false);
last_touch_note = note;
}
}
else if (p.page < 4) { // Main UI
if (tx < 0 || tx > 320 || ty < 35 || ty > 235) return;
int row = (ty - 35) / 50; int col = (tx < 160) ? 0 : 1;
float cellX = (col == 0) ? tx - 5 : tx - 165;
float normVal = constrain(cellX / 150.0f, 0.0f, 1.0f);
if (p.page == 0) {
if(col==0 && row==0) apply_selection((int)(normVal * total_presets));
if(col==0 && row==1 && p.total_files > 0) {
int new_idx = constrain((int)(normVal * p.total_files), 0, p.total_files - 1);
if (p.selected_file_idx != new_idx) { p.selected_file_idx = new_idx; p.req_file_reload = true; p.dirty = true; }
}
if(col==0 && row==2 && finger_released) { p.playing = !p.playing; if(!p.playing) p.req_panic = true; p.dirty = true; finger_released = false; }
if(col==0 && row==3) { p.play_speed = 0.5f + normVal * 1.5f; p.dirty = true; }
if(col==1 && row==0) { p.wave = (int)(normVal * 5); p.dirty = true; }
if(col==1 && row==1) { p.chorus = normVal; p.dirty = true; }
if(col==1 && row==2 && finger_released) { p.page = (p.page + 1) % MAX_PAGES; p.dirty = true; finger_released = false; }
if(col==1 && row==3) { p.gain = normVal; p.dirty = true; }
}
else if (p.page == 1) {
if(col==0 && row==0) p.glide=normVal; if(col==0 && row==1) p.cut=normVal*8000;
if(col==0 && row==2) p.res=normVal; if(col==0 && row==3) p.delay_mix=normVal;
if(col==1 && row==0) p.reverb_mix=normVal; if(col==1 && row==1) p.fm_idx=normVal*5.0f;
if(col==1 && row==2 && finger_released) { p.page = (p.page + 1) % MAX_PAGES; p.dirty = true; finger_released = false; }
if(col==1 && row==3) p.gain=normVal; p.dirty=true;
}
else if (p.page == 2) {
if(col==0 && row==0) p.a=normVal*2.0; if(col==0 && row==1) p.d=normVal*2.0;
if(col==0 && row==2) p.s=normVal; if(col==0 && row==3) p.r=normVal*2.0;
if(col==1 && row==0) p.lfo_f=normVal; if(col==1 && row==1) p.lfo_d=normVal;
if(col==1 && row==2 && finger_released) { p.page = (p.page + 1) % MAX_PAGES; p.dirty = true; finger_released = false; }
if(col==1 && row==3) p.gain=normVal; p.dirty=true;
}
}
}
void core1_entry() {
pinMode(TFT_BL, OUTPUT); digitalWrite(TFT_BL, HIGH);
pinMode(TFT_RST, OUTPUT); digitalWrite(TFT_RST, LOW); delay(50); digitalWrite(TFT_RST, HIGH); delay(50);
tft.init(240, 320); tft.setRotation(1); tft.fillScreen(C_BLACK);
tft.setCursor(40, 100); tft.setTextSize(3); tft.setTextColor(C_CYAN); tft.print("PolySynth");
tft.setCursor(100, 140); tft.setTextSize(2); tft.setTextColor(C_WHITE); tft.print(VERSION_STR);
delay(2000);
int last_pg = -1; uint32_t last_draw = 0;
touch.begin();
while (1) {
// ★ Polling touch frequently is key
handle_touch();
int cur_pg = p.page;
uint16_t theme = (cur_pg==0)?C_CYAN : (cur_pg==1)?C_MAGENTA : (cur_pg==2)?C_ORANGE : (cur_pg==3)?C_GREEN : (cur_pg==4)?C_WHITE : C_RED;
if (cur_pg != last_pg) { tft.fillScreen(C_BLACK); last_pg = cur_pg; p.dirty = true; }
if (p.dirty && (millis() - last_draw > 50)) {
last_draw = millis();
tft.fillRect(0, 0, 320, 25, C_DARK);
tft.setTextColor(theme, C_DARK); tft.setTextSize(1); tft.setCursor(10, 8);
tft.print("P"); tft.print(cur_pg + 1); tft.print(" ");
// ★ USB DIAGNOSTIC DISPLAY ★
tft.setCursor(150, 8);
if(usb_mounted) {
tft.setTextColor(C_GREEN, C_DARK); tft.print("USB:OK ");
} else {
tft.setTextColor(C_RED, C_DARK); tft.print("USB:-- ");
}
if(midi_rx_activity) {
tft.setTextColor(C_YELLOW, C_RED); tft.print("MIDI!");
midi_rx_activity = false; // Reset flash
}
tft.fillRect(260, 0, 60, 25, C_GRAY);
tft.setCursor(270, 8); tft.setTextColor(C_WHITE, C_GRAY); tft.print("NEXT");
if (cur_pg < 3) {
// ... Same drawing logic as before ...
if(cur_pg==0) {
drawCell(0,0,"PRESET",ALL_NAMES[p.preset],p.preset,10,theme);
String fName = "NO FILES"; if(p.total_files>0) fName = formatMidiName(midi_filenames[p.selected_file_idx]);
drawCell(0,1,"FILE",fName,1,1,(p.total_files>0?theme:C_RED));
drawCell(0,2,"PLAY",(p.playing?"ON":"OFF"),p.playing,1,theme);
drawCell(0,3,"SPEED",String((int)(p.play_speed*100))+"%",p.play_speed,2.0,theme);
drawCell(1,0,"WAVE",ALL_NAMES[p.wave],p.wave,10,theme);
drawCell(1,1,"CHORUS",String((int)(p.chorus*100))+"%",p.chorus,1.0,theme);
drawCell(1,2,"PAGE","NEXT",0,1,C_GRAY);
drawCell(1,3,"VOL",String((int)(p.gain*100)),p.gain,1.0,C_WHITE);
}
else if(cur_pg==1) {
drawCell(0,0,"GLIDE",String(p.glide,2),p.glide,1.0,theme); drawCell(0,1,"CUTOFF",String((int)p.cut),p.cut,12000,theme);
drawCell(0,2,"RESON",String(p.res,2),p.res,1.0,theme); drawCell(0,3,"DELAY",String((int)(p.delay_mix*100))+"%",p.delay_mix,1.0,theme);
drawCell(1,0,"REVERB",String((int)(p.reverb_mix*100))+"%",p.reverb_mix,1.0,theme); drawCell(1,1,"FM IDX",String(p.fm_idx,1),p.fm_idx,5.0,theme);
drawCell(1,2,"PAGE","NEXT",0,1,C_GRAY); drawCell(1,3,"VOL",String((int)(p.gain*100)),p.gain,1.0,C_WHITE);
}
else if(cur_pg==2) {
drawCell(0,0,"ATTACK",String(p.a,2),p.a,2.0,theme); drawCell(0,1,"DECAY",String(p.d,2),p.d,2.0,theme);
drawCell(0,2,"SUSTAIN",String(p.s,2),p.s,1.0,theme); drawCell(0,3,"RELEASE",String(p.r,2),p.r,2.0,theme);
drawCell(1,0,"LFO F",String(p.lfo_f*20,1),p.lfo_f,1.0,theme); drawCell(1,1,"LFO D",String(p.lfo_d,1),p.lfo_d,1.0,theme);
drawCell(1,2,"PAGE","NEXT",0,1,C_GRAY); drawCell(1,3,"VOL",String((int)(p.gain*100)),p.gain,1.0,C_WHITE);
}
} else if (cur_pg == 4) { drawKeyboard(); }
else if (cur_pg == 5) { drawSystemPage(); }
p.dirty = false;
}
if (cur_pg == 3) {
// ★ Throttled to 66ms (15 FPS) to allow Touch priority
if(millis() - last_draw > 66) {
tft.fillRect(0, 42, 320, 78, 0);
int cy = 81; for (int i = 0; i < SCOPE_SAMPLES - 1; i++) { int y1 = constrain(cy + (scope_buf[i] / 500), 42, 118); int y2 = constrain(cy + (scope_buf[i+1] / 500), 42, 118); tft.drawLine(i, y1, i+1, y2, C_CYAN); }
if (fft_ready) {
tft.fillRect(0, 120, 320, 100, 0);
FFT.windowing(FFTWindow::Hamming, FFTDirection::Forward); FFT.compute(FFTDirection::Forward); FFT.complexToMagnitude();
for (int i=1; i < 161; i++) { int h = (int)constrain(13.0f * log10f(vReal[i] + 1.0f), 0, 90); uint16_t barColor = C_GREEN; if(h>40) barColor=C_YELLOW; if(h>70) barColor=C_RED; tft.fillRect((i-1)*2, 210-h, 2, h, barColor); }
fft_ready = false;
}
}
}
// No heavy delay
}
}
// ... (Setup/Loop) ...
void setup() {
vreg_set_voltage(VREG_VOLTAGE_1_20); delay(10);
set_sys_clock_khz(250000, true);
Serial1.setTX(0); Serial1.begin(31250);
SPI1.setSCK(TFT_SCLK); SPI1.setTX(TFT_MOSI); SPI1.begin();
pinMode(TOUCH_RST, OUTPUT); digitalWrite(TOUCH_RST, HIGH); delay(50); digitalWrite(TOUCH_RST, LOW); delay(20); digitalWrite(TOUCH_RST, HIGH); delay(100);
Wire1.setSDA(TOUCH_SDA); Wire1.setSCL(TOUCH_SCL); Wire1.begin(); Wire1.setClock(400000);
if(LittleFS.begin()) { scanMidiFiles(); }
// ★ USB HOST START (Always ON) ★
USBHost.begin(0);
for (int i=0; i<SINE_SIZE; i++) sineTbl[i] = sinf(2.0f * PI * i / SINE_SIZE);
i2s.setBCLK(I2S_BCLK); i2s.setDATA(I2S_DOUT); i2s.begin(SAMPLE_RATE);
apply_selection(0);
multicore_launch_core1(core1_entry);
}
void loop() {
// ★ USB HOST TASK ★
USBHost.task();
update_sequencer();
if (p.req_panic) { panic(); p.req_panic = false; }
if (p.req_file_reload) { if (midiFile) midiFile.close(); p.playing = false; num_tracks_active = 0; p.req_file_reload = false; }
float lfo_val = sinf(p.lfo_ph) * p.lfo_d * 10.0f;
p.lfo_ph += (2.0f * PI * (p.lfo_f * 20.0f)) / SAMPLE_RATE;
if(p.lfo_ph >= 2.0f * PI) p.lfo_ph -= 2.0f * PI;
float g_factor = powf(0.001f, 1.0f / (max(p.glide, 0.001f) * SAMPLE_RATE));
float q = 1.0f - p.res;
for (int s=0; s<AUDIO_BLOCK; s++) {
float mix = 0;
for (int i=0; i<POLYPHONY; i++) {
if (voices[i].active) {
if (!voices[i].is_drum && p.glide > 0) voices[i].freq = voices[i].target_freq + (voices[i].freq - voices[i].target_freq) * g_factor;
else voices[i].freq = voices[i].target_freq;
float mod = 0;
if(!voices[i].is_drum && p.fm_idx > 0) mod = voices[i].freq * p.fm_idx * sinf(voices[i].ph * 2.0f * PI);
float target_cut = (p.wave == 4) ? voices[i].freq : p.cut;
if (s == 0) voices[i].f_coeff = 2.0f * sinf(PI * constrain(target_cut, 50, 15000) / SAMPLE_RATE);
float cur_ph = voices[i].ph; float osc_out = 0;
if (voices[i].is_drum) { osc_out = (voices[i].note < 40) ? sinf(cur_ph * 20.0f * PI) + (((int32_t)xorshift32()) / 2147483648.0f) * 0.3f : ((int32_t)xorshift32()) / 2147483648.0f; }
else {
if(p.wave==0) osc_out = sineTbl[(int)(cur_ph*SINE_SIZE)%SINE_SIZE];
else if(p.wave==1) osc_out = 2.0f*(cur_ph-0.5f);
else if(p.wave==2) osc_out = (cur_ph < 0.5f) ? (4.0f * cur_ph - 1.0f) : (3.0f - 4.0f * cur_ph);
else if(p.wave==3) osc_out = (cur_ph<0.5f)?0.5f:-0.5f;
else osc_out = ((int32_t)xorshift32()) / 2147483648.0f;
}
voices[i].low += voices[i].f_coeff * voices[i].band;
voices[i].band += voices[i].f_coeff * (osc_out - voices[i].low - q * voices[i].band);
float env = voices[i].env;
if(voices[i].is_drum) env *= (voices[i].note < 40) ? 0.9f : 0.6f;
mix += voices[i].low * env * 0.20f;
voices[i].ph += (voices[i].freq + mod + lfo_val)/SAMPLE_RATE;
if(voices[i].ph >= 1.0f) voices[i].ph -= 1.0f;
float stp = 1.0f / SAMPLE_RATE;
float atk = voices[i].is_drum ? 0.001f : p.a;
float dec = voices[i].is_drum ? 0.1f : p.d;
float sus = voices[i].is_drum ? 0.0f : p.s;
float rel = voices[i].is_drum ? 0.1f : p.r;
if (voices[i].stage == 1) { voices[i].env += stp/max(atk,0.001f); if(voices[i].env>=1.0f) voices[i].stage=2; }
else if (voices[i].stage == 2) { voices[i].env -= (stp/max(dec,0.001f))*(1.0 - sus); if(voices[i].env<=sus) voices[i].stage=3; }
else if (voices[i].stage == 4) { voices[i].env -= stp/max(rel,0.001f); if(voices[i].env<=0) { voices[i].active=false; voices[i].note=-1; } }
}
}
float d_out = delayBuf[delay_idx]; delayBuf[delay_idx] = mix + d_out * (0.5f + p.chorus * 0.2f); delay_idx = (delay_idx + 1) % DELAY_LEN;
float dry_plus_delay = mix + d_out * p.delay_mix;
float c1 = comb1Buf[c1_idx]; comb1Buf[c1_idx] = dry_plus_delay + c1 * 0.7f; c1_idx = (c1_idx + 1) % COMB1_LEN;
float c2 = comb2Buf[c2_idx]; comb2Buf[c2_idx] = dry_plus_delay + c2 * 0.65f; c2_idx = (c2_idx + 1) % COMB2_LEN;
float rev_in = c1 + c2;
float ap_out = apBuf[ap_idx]; float ap_new = rev_in + ap_out * 0.5f; apBuf[ap_idx] = ap_new; ap_idx = (ap_idx + 1) % AP_LEN;
float final_rev = ap_new - rev_in;
float output = (dry_plus_delay + final_rev * p.reverb_mix) * p.gain * 12000.0f;
int16_t dry_int = (int16_t)constrain(output, -32000, 32000);
i2s.write(dry_int); i2s.write(dry_int);
if (p.page == 3) {
if(s_ptr < SCOPE_SAMPLES) scope_buf[s_ptr++] = dry_int; else s_ptr = 0;
if (!fft_ready) { vReal[f_ptr] = (float)dry_int; vImag[f_ptr] = 0; if(++f_ptr >= FFT_SAMPLES) { f_ptr = 0; fft_ready = true; } }
}
}
}
// ★ FIXED CALLBACKS (Updated for new library) ★
extern "C" {
// ★ FIXED SIGNATURE: use const tuh_midi_mount_cb_t *
void tuh_midi_mount_cb(uint8_t idx, const tuh_midi_mount_cb_t *mount_cb_data) {
usb_mounted = true;
}
void tuh_midi_unmount_cb(uint8_t idx) {
usb_mounted = false;
}
void tuh_midi_rx_cb(uint8_t d, uint32_t n_p) {
uint8_t pkt[4];
while (tuh_midi_packet_read(d, pkt)) {
midi_rx_activity = true;
uint8_t st = pkt[1] & 0xF0, d1 = pkt[2], d2 = pkt[3];
float val = d2 / 127.0f;
if (st == 0x90 && d2 > 0) {
float tf = 440.0f * powf(2.0f, (d1 - 69.0f) / 12.0f);
for(int i=0; i<POLYPHONY; i++) if(!voices[i].active) {
voices[i].note=d1; voices[i].target_freq=tf;
if(p.glide==0) voices[i].freq=tf;
voices[i].ph=0; voices[i].stage=1; voices[i].env=0; voices[i].active=true;
voices[i].low=0; voices[i].band=0;
p.note_active = true; break;
}
} else if (st == 0x80 || (st == 0x90 && d2 == 0)) {
bool any_active = false;
for(int i=0; i<POLYPHONY; i++) {
if(voices[i].note==d1) voices[i].stage=4;
if(voices[i].active && voices[i].stage!=4) any_active = true;
}
p.note_active = any_active;
}
if (st == 0xB0) {
if (d1 == 7) { p.page = (d2 * 4) / 128; p.dirty = true; }
else if (d1 == 8) { p.gain = val; p.dirty = true; }
else {
switch(p.page) {
case 0:
if(d1==1) apply_selection((d2 * total_presets) / 128);
if(d1==2 && p.total_files>0) { int nx=(d2*p.total_files)/128; if(p.selected_file_idx!=nx) { p.selected_file_idx=nx; p.req_file_reload=true; p.dirty=true; }}
if(d1==3) { bool q=(d2>64); if(p.playing!=q){p.playing=q; if(!q)p.req_panic=true; p.dirty=true;} }
if(d1==4) { p.play_speed = 0.5f+val*1.5f; p.dirty=true; }
if(d1==5) { p.wave=(d2*5)/128; p.dirty=true; }
if(d1==6) { p.chorus=val; p.dirty=true; }
break;
case 1:
if(d1==1)p.glide=val; if(d1==2)p.cut=val*8000.0f;
if(d1==3)p.res=val; if(d1==4)p.delay_mix=val;
if(d1==5)p.reverb_mix=val; if(d1==6)p.fm_idx=val*5.0f;
p.dirty = true; break;
case 2:
if(d1==1)p.a=val; if(d1==2)p.d=val; if(d1==3)p.s=val; if(d1==4)p.r=val;
if(d1==5)p.lfo_f=val; if(d1==6)p.lfo_d=val; p.dirty = true; break;
}
}
}
}
}
}
</details>
教訓
- タッチパネルのデータ仕様はデータシートを読むか、サンプルコードを徹底的に解析する: 8bitだと思い込んでいたら、実は12bit変則パッキングだった。
- ゴーストタッチ対策: 静電容量式タッチパネルでも、ドライバレベルでのチャタリング除去や静止画検知が必要な場合がある。
- USBホスト機能はIDE設定が命: コードが正しくても、コンパイラの設定(USB Stack)が間違っていればハードウェアは動かない。これが今回の最大の落とし穴でした。
- ライブラリの更新履歴: エラーメッセージの
conflicting declarationは、API仕様変更の証拠。ヘッダファイルを確認するのが一番の近道。
USB 接続のmidi keyboardの認識に苦労
Grokの次のアドバイスで救われました。
Arduino IDEのライブラリフォルダを開く Windowsの場合: C:\Users\[ユーザー名]\AppData\Local\Arduino15\packages\rp2040\hardware\rp2040\[バージョン]\libraries\Adafruit_TinyUSB_Arduino\src\arduino\ports\rp2040\
そこに tusb_config_rp2040.h というファイルがあります。
そのファイルをテキストエディタで開き、以下の2箇所を修正:
① MIDI Hostを有効にする 以下の行を探して(なければ追加):
#define CFG_TUH_MIDI 1(0 になっていたら1に変更)
② 列挙バッファを大きくする(MPK mini mk3の記述子が長いため必須) 以下の行を探して:
#define CFG_TUH_ENUMERATION_BUFSIZE 512Waveshare RP2350-Touch-LCD-2
| 機能グループ | GPIO番号 | 用途 / 接続先 | インターフェース | 備考 |
|---|---|---|---|---|
| LCD (ST7789T3) | GPIO15 | LCD_BL (バックライト PWM制御) | GPIO (PWM) | 占有 |
| LCD | GPIO16 | LCD_DC (Data/Command) | SPI | 占有 |
| LCD | GPIO17 | LCD_CS (Chip Select) | SPI | 占有 |
| LCD | GPIO18 | LCD_CLK (SCK / Clock) | SPI | 占有 |
| LCD | GPIO19 | LCD_DIN (MOSI / Data In) | SPI | 占有 |
| LCD | GPIO20 | LCD_RST (Reset) | GPIO | 占有 |
| Touch (CST816D) + IMU (QMI8658) | GPIO12 | TP_SDA / IMU_SDA (I2C データ) | I2C | 共有 |
| Touch / IMU | GPIO13 | TP_SCL / IMU_SCL (I2C クロック) | I2C | 共有 |
| Touch / IMU | GPIO14 | TP_INT / IMU_INT1 (割り込み) | GPIO | 共有(割り込み) |
| TFカード (SD) | GPIO24 | SD_SCLK (Clock) | SPI | 占有 |
| TFカード | GPIO25 | SD_CS (Chip Select) | SPI | 占有 |
| TFカード | GPIO26 | SD_MISO (DO / Data Out) | SPI | 占有 |
| TFカード | GPIO27 | SD_MOSI (DI / Data In) | SPI | 占有 |
| カメラ (DVP) | GPIO0 | CAM_D0 (Data 0) | Parallel DVP | 占有 |
| カメラ | GPIO1 | CAM_D1 | Parallel DVP | 占有 |
| カメラ | GPIO2 | CAM_D2 | Parallel DVP | 占有 |
| カメラ | GPIO3 | CAM_D3 | Parallel DVP | 占有 |
| カメラ | GPIO4 | CAM_D4 | Parallel DVP | 占有 |
| カメラ | GPIO5 | CAM_D5 | Parallel DVP | 占有 |
| カメラ | GPIO6 | CAM_D6 | Parallel DVP | 占有 |
| カメラ | GPIO7 | CAM_D7 | Parallel DVP | 占有 |
| カメラ | GPIO8 | CAM_VSYNC (Vertical Sync) | DVP | 占有 |
| カメラ | GPIO9 | CAM_HREF (Horizontal Reference) | DVP | 占有 |
| カメラ | GPIO10 | CAM_PCLK (Pixel Clock) | DVP | 占有 |
| カメラ | GPIO11 | CAM_XCLK (Master Clock出力) | GPIO (クロック) | 占有 |
| カメラ | GPIO21 | CAM_PWDN (Power Down) | GPIO | 占有 |
| バッテリー監視 | GPIO28 | BAT_ADC (電池電圧 ADC入力) | ADC | 占有 |