認識に邪魔な線をcv2.HoughLinesPの機能で判定しているわけですが、この関数では、線として認識した座標(x0,y0)-(x1,y1)のリストを返します。
この座標群から, Xmin,Xmax,Ymin,Ymaxを求めると、問題マスの左上と右下の座標が分かります。
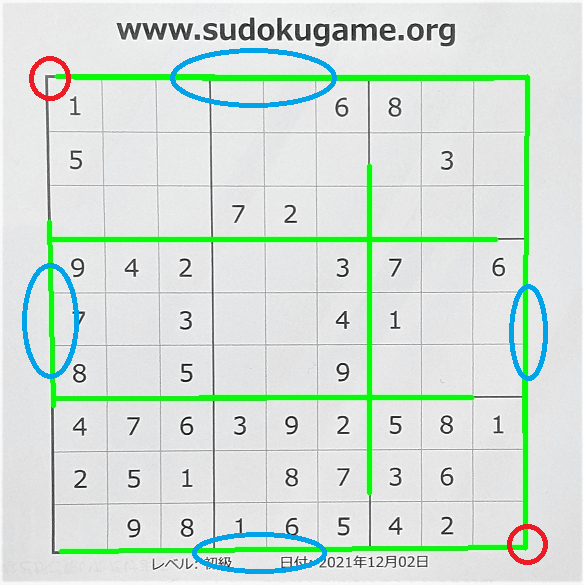
線を認識する際に、少なくても左端と右端の垂直線、水平線の上端、下端の線を認識できていることが条件です。
次の画像では、緑が線として認識した箇所。4個の青で囲んだ線が、位置の判定に必要な線です。4本の線の座標から、赤丸の座標も算出できます。
これらの座標から、1文字毎の画像を切り出して個々の画像を認識するよう実装してみました。
import streamlit as st
import cv2
from PIL import Image # 画像処理ライブラリ
#from matplotlib import pyplot as plt # データプロット用ライブラリ
import numpy as np # データ分析用ライブラリ
#import os # os の情報を扱うライブラリ
import pytesseract # tesseract の python 用ライブラリ
import unicodedata
def remove_control_characters(s):
return "".join(ch for ch in s if unicodedata.category(ch)[0]!="C")
def erase_lines(img,img_thresh,th1):
# OpenCVで直線の検出
# https://qiita.com/tifa2chan/items/d2b6c476d9f527785414
img2 = img.copy()
img3 = img.copy()
gray = cv2.cvtColor(img_thresh, cv2.COLOR_BGR2GRAY)
gray_list = np.array(gray)
gray2 = cv2.bitwise_not(gray)
gray2_list = np.array(gray2)
lines = cv2.HoughLinesP(gray2, rho=1, theta=np.pi/360, threshold=th1, minLineLength=150, maxLineGap=5)
xmin,ymin=500,500
xmax,ymax=0,0
if lines is not None:
for line in lines: # Xmin,Xmax,Ymin,Ymaxの算出
x1, y1, x2, y2 = line[0]
if x1<xmin:
xmin=x1
if y1<ymin:
ymin=y1
if x1>xmax:
xmax=x1
if y1>ymax:
ymax=y1
# 緑色の線を引く
red_lines_img = cv2.line(img2, (x1,y1), (x2,y2), (0,255,0), 3)
red_lines_np=np.array( red_lines_img)
#cv2.imwrite("calendar_mod3.png", red_lines_img)
# 線を消す(白で線を引く)
no_lines_img = cv2.line(img_thresh, (x1,y1), (x2,y2), (255,255,255), 3)
no_lines=np.array( no_lines_img)
dx=int(0.5+(xmax-xmin)/9)
dy=int(0.5+(ymax-ymin)/9)
sx=int(0.5+dx*0.2)
sy=int(0.5+dy*0.2)
st.write(xmin,ymin,xmax,ymax,dx,dy)
peaces=[]
for y in range(9):
for x in range(9):
p = xmin + x*dx + sx
q = ymin + y*dy + sy
cv2.rectangle(no_lines,(p,q),(p+dx-sx,q+dy-sy),(0,0,255),1)
peaces.append(cv2.cvtColor(no_lines_img[q:q+dy-sy,p:p+dx-sx],cv2.COLOR_BGR2RGB))
#st.image(peace,caption=str(x)+','+str(y))
im_h= cv2.hconcat([red_lines_img, img_thresh])
else:
im_h = None
no_lines = img_thresh
return im_h, no_lines,peaces
def main():
st.title('文字認識の実験')
col1, col2 ,col3, col4 = st.columns([3,1,1,1])
KEI = None
with col1:
uploaded_file = st.file_uploader("画像ファイルを選択してアップロード")
if uploaded_file is not None:
img = Image.open(uploaded_file)
img = np.array(img)
th2 = st.slider(label='2値化の閾値',min_value=0, max_value=255, value=100)
th1 = st.slider(label='線消去の閾値',min_value=0, max_value=255, value=100)
with col2:
LNG = st.selectbox("言語選択",['eng','jpn'])
with col3:
KEI = st.checkbox('線削除')
with col4:
OCR = st.checkbox('OCR実行')
ret, img_thresh = cv2.threshold(img, th2, 255, cv2.THRESH_BINARY)
im_h = cv2.hconcat([img, img_thresh])
st.image(im_h, caption='元画像<--->2値化画像')
if KEI:
im_h, no_lines, peaces = erase_lines(img,img_thresh,th1)
if im_h is None:
st.warning('No line detectd')
else:
new_image = cv2.cvtColor(im_h, cv2.COLOR_BGR2RGB)
st.image(new_image,caption='線を削除した画像')
else:
no_lines=img_thresh
if OCR:
st.subheader('---認識結果---')
#txt = pytesseract.image_to_string(no_lines, lang="eng",config='--psm 11')
conf='-l ' + LNG + ' --psm 6 outputbase digits'
n=0
row=''
for peace in peaces:
txt=pytesseract.image_to_string(peace, config=conf)
txt=remove_control_characters(txt)
if txt.isdigit():
ans=str(txt)+' '
else:
ans='--'
row=row+ans
n=n+1
if(n==9):
st.write(row)
row=''
n=0
if __name__ == '__main__':
main()認識結果:100%の正解
1 --------6 8 ----
5 ------------3 --
------7 2 --------
9 4 2 ----3 7 --6
7 --3 ----4 1 ----
8 --5 ----9 ------
4 7 6 3 9 2 5 8 1
2 5 1 --8 7 3 6 --
--9 8 1 6 5 4 2 --